Anatomy of data nodes in Elasticsearch p. 1
This is the follow-up to my previous article about Elasticsearch clusters. Last time, we explored the world of master nodes. This time we will take a look at data nodes in Elasticsearch which store the actual data. This topic will be split into two parts. The part one describes indices: how they work, and what sharding and replication is. In the part 2 we will watch, what happens during a real failure.
tl;dr;
The indexed data is organized into indices, which can spread across multiple nodes thanks to sharding. This improves performance, but reduces resiliency, therefore we need replication. Elasticsearch puts more responsibility on developers to properly configure shards and replicas, than other storage engines.
Elasticsearch data nodes
The goal of data nodes is storing the data and performing the search operations on them. The main unit are documents, stored in multiple indices. An index is a data structure specific to Elasticsearch, tuned for full text searching. The structure of the index is called index mapping. It describes the available fields, their types and other properties. At the first sight, this looks like database tables, but there is also one major difference.
What is so special about indices? It’s the unique nature of the searching process. In Elasticsearch, we are not restricted to searching only one index at a time. Instead, we can run a query over multiple (possibly all) indices and get a unified set of results. Such searching works even, if the indices have different mappings.
This property of indices changes the way how we should think about them. In other databases, we would likely create separate collections for each entity. Here, a better way is either keeping multiple document types in a single index, or creating many indices for a single entity. Elasticsearch excels at indexing time series that grow over time, such as logs. We can create a new index per week, and regularly delete the oldest indices to provide data retention.
In short…
Avoid using indices like regular database tables or collections. Make use of their properties.
Sharding
Elasticsearch is a distributed system. The indices can grow very large, therefore to help scaling them, we can use shards. Sharding splits a single, big index into smaller shards, so that each shard stores only a subset of data. Then, we can put them into distinct nodes to improve search speed. Searching works by running a query on all shards, and then combining partial results into the final set. The currently elected master node decides which shard goes to what node.
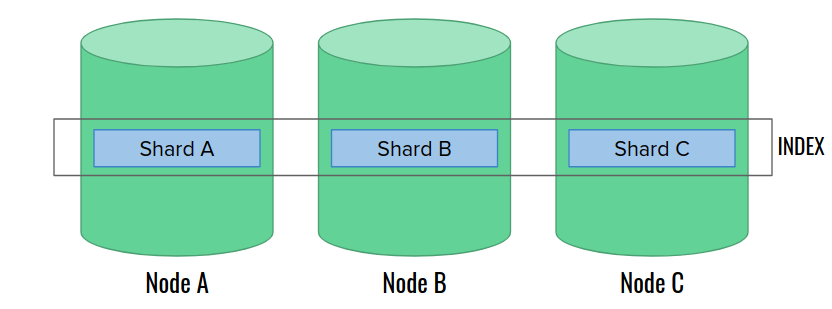
In Elasticsearch, we cannot change the number of shards after index creation. It’s mostly because we need to reliably assign every document into a shard. An attempt to change the shard number would destroy the existing association. Basically we would need to re-index everything. Although there are sharding algorithms that allow changing the shard count, Elasticsearch cannot use them. The reason is hidden in the internals: ES is built on top of Apache Lucene library, and each shard is in fact a single Lucene index.
Sharding improves search and indexing speed, but it has a hidden cost. It’s easier to loose the data – if any of the nodes fails, the index becomes corrupted.
Replication
To prevent resiliency issues produced by shards, we need replication. For each shard, we create one or more copies (replicas) stored on different nodes. One of the replicas becomes a primary shard. We write all the new data firstly into the primary shard, and then replicate them to other replicas. If we loose any replica due to node failure, we can rebuild it on another node from other copies. If we loose a primary shard, another replica can be promoted by the master node. The golden rule of shard allocation is that two replicas of the same shard can never land on the same node.
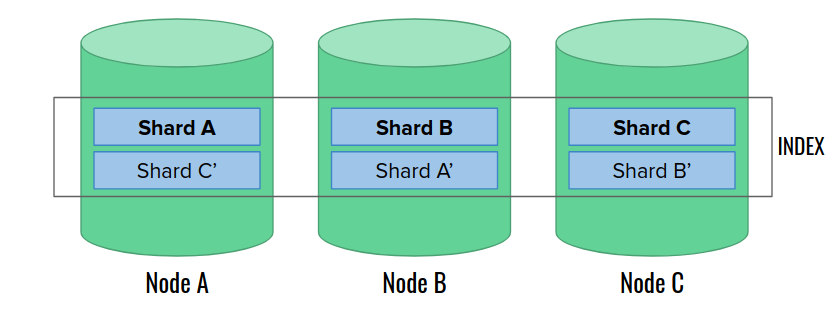
What do replicas give us? Let’s see:
- better resiliency: a shard with two replicas can withstand the loss of two copies,
- better search speed: replicas can also run search queries,
- worse indexing speed: we need to replicate each change to additional nodes.
Fine-tuning data nodes
In normal databases, the database structure is usually static. We set up everything once, and many smaller services can even happily live with the default settings. On the other hand, Elasitcsearch puts much more responsibility on us – devs – to fine-tune everything. Here are a couple of aspects that we need to consider during designing our cluster:
- shard number is constant: after creating an index, we cannot change the number of shards. The documentation recommends to store between 10 GB and 50 GB of data in a single shard,
- replica number is variable: we can change the number of replicas at any time,
- number of data nodes is variable: we can add or remove data nodes at any time,
- shards cost CPU and memory resources: a couple of larger shards usually use fewer resources than a large set of small shards,
- search queries utilize 1 thread per shard: usually it speeds up the search process. However, beware of the thread pool size! A large number of search queries running on many small shards can quickly deplete the available threads, and effectively – slow down the cluster!
- max shard count proportional to JVM heap size: shard metadata is stored in memory for faster access. Therefore, the amount of memory limits the maximum number of shards that we can host on a single node. The documentation suggests 20 or fewer shards per 1 GB of heap memory. Replicas also count!
Preferred work model
We can now see that the limits showed above clearly favor a different way of using indices, than we know from other databases. Firstly, we have an explicit max index size: shard count * [10 .. 50 GB]. To index more data, we should simply create extra indices, and use multi-index queries. Secondly, and contrary to the previous point, creating many small indices can quickly deplete our cluster of resources: memory and threads. Our goal is finding a good balance.
One more aspect to consider is the number of fields per index. In Elasticsearch, we have a strict max field limit per index equal to 1024 fields. We can increase it, but again – the cost is worse performance. Therefore, we should also check what fields are really worth indexing. Purely technical or sparse fields usually are not.
In short…
Pay attention to the number of shards, indices, and index fields to avoid depleting node resources for unnecessary stuff.
Managing replica counts
Contrary to other settings, changing replica count is very simple (although costly) operation. Here are a couple of hints to make a good use of that:
- for initial indexing, create an index without replicas. Add them once you index all the data. This is usually faster than indexing with replication,
- for indices that hold fresh, frequently updated data, consider using fewer replicas to optimize them for indexing speed,
- for indices that hold archival, rarely changed data, add additional replicas to increase searching speed,
- consider creating separate data nodes for the “hot” and “cold” indices created above. Elasticsearch gives you tools for controlling the shard allocation process. In this way, you can make sure that you store each index on a data node optimized for the given use case.
Summary
We can see that managing data nodes requires more attention from us, than it is for other storage technologies. Especially, we need to carefully plan when to create indices, and what should be the best shard and replica counts for each of them. In the second part, we will focus entirely on failure tolerance. Stay tuned!
