Anatomy of master nodes in Elasticsearch
Elasticsearch is a search engine written in Java, based on Apache Lucene library. As a distributed system, it creates certain challenges for reliability and availability of our data. But what actually happens if we misconfigure our cluster and how to make it safe? In this article, we will take a deeper look of how master nodes in Elasticsearch work, and try to answer this question by looking at some sample failures.
tl;dr;
A master node in Elasticsearch manages the state of the cluster, and is elected from a group of master-eligible nodes. The voting process requires an odd number of master-eligible nodes in the cluster and a quorum, in order to be reliable.
Master-eligible nodes
The nodes in Elasticsearch clusters can assume different roles. The heart of the cluster is so-called master node which is responsible for the managing it. By “managing” we understand keeping track of all the indices, their shards and replicas, assigning them to individual data nodes, etc. In addition, when some data node goes down, master node coordinates the recovery action: reallocation of lost shards to different nodes and recovering them from available replicas. Keeping cluster state consistent is critical to the health of Elasticsearch, therefore we can have only one master node in our installation.
However, a single master node is also a single (and quite critical) point of failure. In fact, we don’t assign this role by hand. Instead, we add a whole group of so-called “master-eligible nodes” to our cluster and they elect the master from themselves through a voting process. They keep an up-to-date copy of the cluster state, synchronized from master, so that – in case of inevitable failure – it is possible to quickly elect a new master.
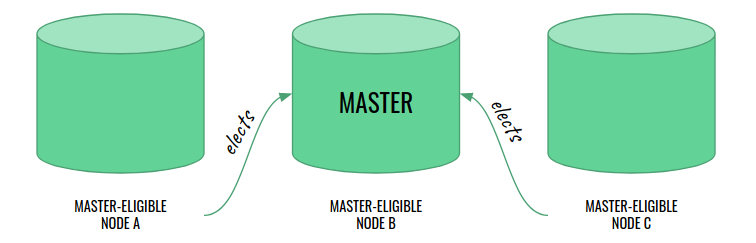
It turns out that the election process is not reliable unless we meet two conditions:
- the cluster contains an odd number of master-eligible nodes,
- there is a quorum: at least 50% of all master-eligible nodes must be available for voting.
Split-brain
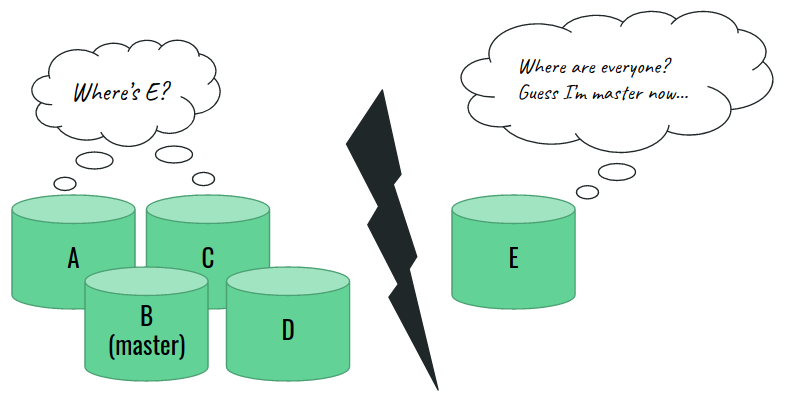
In the example below, we will show a classical type of failure known as split-brain. It shows why the odd number of nodes is so important. Let’s say that our cluster contains 4 master-eligible nodes with node A previously elected as a master:
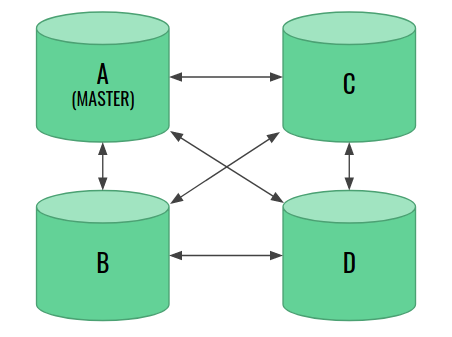
Now, a failure occurs that cuts the network connection between two pairs of nodes. Each pair knows hothing about what has happened to the other two. Have they crashed? Is this a planned restart? Is there a temporary network connection issue? They have no idea. Eventually, each pair runs the voting and elects their own master.
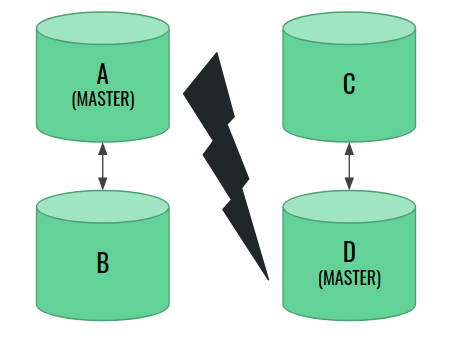
Eventually, the connection goes back. The nodes see one another again, and the new problem arises: we have two master nodes, and one should step down from this role. It turns out that this is not actually possible and our cluster is doomed.
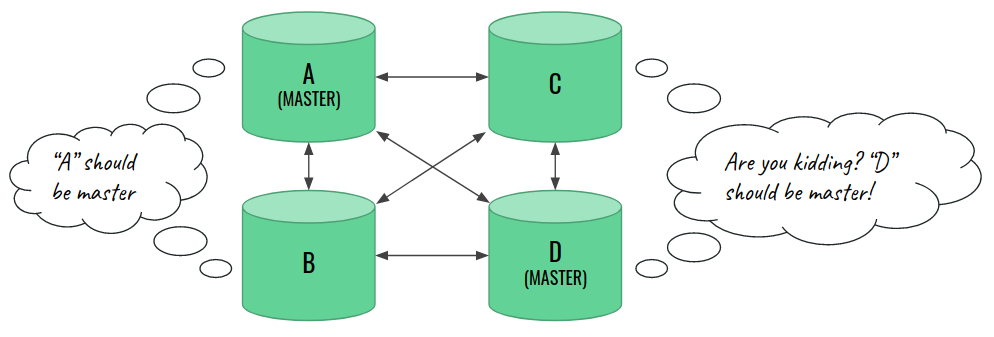
Root cause
The number of nodes is even, and the election process takes into account factors, such as “who has the newest cluster state”. In our scenario, we ran into an unresolvable tie. Each pair would claim that “their” master is the best. At the same time, they would not be able to outvote the others. But this is only half of the problem. Both masters operated their parts of cluster independently for some time, and their copies simply diverged. There may be changes which conflict with what the other master did. This is split-brain. Having an odd number of nodes allows us avoiding such a tie (one side would be bigger), but it does not fully solve the issue yet.
In short…
Odd number of master-eligible nodes is a must-have precondition to avoid unresolvable tie in the master election process, due to split-brain. However, it is not sufficient… we also need quorum for that!
Quorum
Putting things simply: too small groups of master-eligible nodes in Elasticsearch should not attempt to elect master at all. Even if the majority would eventually outvote them, a single renegade master can make mess in our data nodes. In the worst scenario, the new index creation request could land in the “wrong” part of the cluster. It would be later erased by the rightful master, together with all data in it.
Starting from version 7.0, Elasticsearch enforces quorum automatically. In older versions we had to manually specify the minimum number of master nodes, using the following option:
discovery.zen.minimum_master_nodes = ⌊N/2⌋ + 1In Elasticsearch prior to version 7.0, it was very easy to reproduce the negative consequences of operating a cluster without quorum – below, I present a sample scenario:
- let’s assume that A is master
- don’t set
discovery.zen.minimum_master_nodes - shutdown nodes A and B; C elects itself as a new master
- create an index foo and index some data into it
- shutdown node C
- start nodes A and B
- start node C
The index creation request from step 4 is handled by the node C. But later we shutdown it, and neither A, nor B knows that C elected itself a master for a brief period of time. In step 7, node C can no longer join as a master (it is immediately outvoted by A and B). As a result, we also loose index foo, since the actual master knows nothing about it. If we paid attention to quorum, we would not allow C to elect itself as a master. Of course, the cluster would then stop in step 3, but at least we would keep the consistency.
In short…
Quorum guarantees that in the election process, there is always at least 1 node which remembers the last valid cluster state, and that the newly elected master would never be outvoted later by any absent node.
Practical considerations
The two conditions have some implications for us:
- we shall never disable more than half of master-eligible nodes at the same time: the cluster would go to RED state, until enough nodes join back,
- it is not possible to use the master election process for an automatic switch-over between two data centers. One of them would always have less than 50% of master-eligible nodes: electing master would not be possible if the second data center goes down.
- the two conditions are a must-have to meet any high availability requirements.
Summary
To sum up, Elasticsearch cluster management is not as hard as it may look like. Before we end, I’d like to list a couple of real world errors and mistakes made by developers that I observed in real life:
- adding an even number of master-eligible nodes to the clusters,
- before Elasticsearch 7.0: not configuring discovery.zen.minimum_master_nodes (documentation)
- computing quorum for data nodes/replica counts (quorum has nothing to do with them!)
Avoid them to make sure that your cluster is safe and resilient. To learn more about Elasticsearch, take also a look at the follow-up article “Anatomy of data nodes in Elasticsearch p. 1“!
