Barriers in LMAX Disruptor
LMAX Disruptor is a high performance inter-thread messaging library for Java. When the first version appeared several years ago, it made a lot of buzz on the Internet thanks to the innovative approach to concurrency. This article focuses on event consumers and barriers in LMAX Disruptor. Barriers are an important part of Disruptor architecture. They prevent one consumer from overtaking another. We will show how to use them.
tl;dr;
We can create a barrier by using .handleEventsWith() and .then() DSL methods for registering the event consumers.
How Disruptor works?
Disruptor was created by a financial trading company LMAX. At some point, they faced a challenge to process efficiently 6 million trades per second. They quickly realized that achieving such throughput with database transactions and locks is hardly possible. Instead, they came up with a design based on event sourcing technique, where all the business logic ran in a single thread. Every trade was a simple event processed sequentially.
The heart of the technology is Disruptor. It is a ring buffer data structure of a constant size. There is one event producer which writes incoming events to the buffer cells. We also have one or more consumers consumers that read them. The producer starts overwriting old events once it completes the round. However, it must pay attention not to overtake the last consumer.
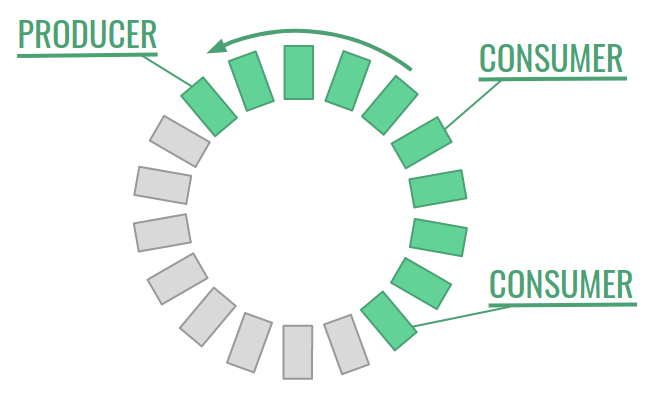
Our use case
Having one producer and multiple consumer is the standard way of using Disruptor. The producer is the source of events, and each consumer executes a single action on them. One of the consumers is of course the business logic. We must also take care of things like recovery, debugging and resiliency, therefore we also need e.g. a consumer for writing events to the journal and another one for replicating them to another machine.
Each consumer reads all the messages from the buffer at its own speed. However, usually we have some dependencies between them. The business logic consumer definitely should not process events that haven’t been written to the journal yet or replicated. We need a way to tell Disruptor about thouse dependencies. This is where barriers come into the scene.
Example code
The API for creating barriers changed a bit between the very first versions of Disruptor and today. Even the user guide does not discuss them much. Fortunately, the API is very easy to use and finding it is not so hard, too. Below, we can see an example setup:
public class App {
private static final int BUFFER_SIZE = 1024;
private static final int EVENT_COUNT = 4096;
private static final Logger log = LoggerFactory.getLogger(App.class);
public static void main(String[] args) {
Disruptor<Event> disruptor = new Disruptor<>(
Event::new, BUFFER_SIZE, Executors.defaultThreadFactory() // 1
);
disruptor
.handleEventsWith(
new Consumer("journal"),
new Consumer("replicate"))
.then(new Consumer("logic")); // 2
disruptor.start();
produceSomeEvents(disruptor);
disruptor.shutdown();
}
private static void produceSomeEvents(Disruptor<Event> disruptor) {
RingBuffer<Event> ringBuffer = disruptor.getRingBuffer();
for (int i = 0; i < EVENT_COUNT; i++) {
var current = i;
ringBuffer.publishEvent(
(event, sequence) -> event.value = current // 3
);
}
}
public static class Event {
private int value;
}
public static class Consumer implements EventHandler<Event> {
private final String name;
public Consumer(String name) {
this.name = name;
}
// 4
@Override
public void onEvent(Event event, long sequence, boolean endOfBatch) {
log.info(name+": " + event.value);
}
}
}This is a complete example. Let’s take a look how it works:
- when we create Disruptor, we specify the ring buffer size and the event factory.
- this is how we create a barrier.
handleEventsWith()registers two consumers that can work concurrently. Withthen()we register the third consumer that can never overtake the former two. - publishing events is about using
publishEvent()method and writing the new data to the pre-allocated objects. Note that older versions of Disruptor did not support lambda syntax here, and we had to create a class implementingEventProducer. - each consumer has one method
onEvent()that consumes a single event. Since all events are mutable objects, it is possible to write to them. We can use that to leave some extra information for consumers behind the barrier.
Event mutability
We may easily notice that Disruptor pre-allocates all events in the ring buffer and never frees them. This is also why our event objects are mutable. Otherwise, we couldn’t write anything to them! We can explain this suprising move of the authors on the ground of modern hardware and garbage collection.
Mechanical sympathy
One of Disruptor’s goals is achieving high throughput and minimizing latency. The authors had previous experience with traditional distributed architectures, and took a closer look how modern hardware and software (notably JVM) works. At hardware side we can consider:
- CPU caching: modern CPU-s have three levels of cache. Reading the frame from the cache is orders of magnitude faster than reading it from RAM,
- number of CPU cores: determines how many truly concurrent operations our machine can do,
- cost of locking: blocking and thread and waking it up later is much more costly today than in the past. Not only we need to switch the CPU context – the cache is also erased.
I have a a real-world example that greatly shows the costs of ignoring the hardware. I once benchmarked a system that ran tens of small services on a single CPU core. In idle state, everything was OK, but if we started adding some traffic, thread context switching quickly consumed 50% of CPU time. The developers wrote most of the services as multi-threaded apps, but due to hardware limits there was no benefit of it. In fact, additional threads made things worse.
Disruptor works the best if we know our hardware. We can optimize the size of the ring buffer, waiting strategies, thread pool size etc. for our CPU. This property of a software is called mechanical sympathy.
In short…
Do not ignore the properties of your hardware while writing concurrent code. Especially, avoid using threads if you have only one CPU core!
Garbage collection
At the software side, we must remember that our service runs in a virtual machine that has its own quirks. Normally, creating a large number of short-lived objects is not an issue. JVM manages them very efficiently, and the garbage collector cleans them up quickly, too. However, for critical services the mere existence of the garbage collection can be a problem. When the garbage collector starts cleaning the memory, it must pause the execution of our code. Those pauses are hardly predictable. We cannot control when they happen by design, but we can minimize the risk of starting the garbage collection. How? By creating fewer objects and re-using the existing ones. And this is what Disruptor does. It creates all objects in advance, so that there is no reason for garbage collector to start: the number of objects is constant, and they are all in use.
Conclusion
Disruptor is a great example of thinking out-of-the-box. Even if not every project can benefit from it, I have always showed it on my concurrency workshops. It is a good case study to learn how we can increase performance by simply understanding our hardware.
Sample code
Find a complete example on GitHub: zone84-examples/barriers-lmax-disruptor
