Creating batches with Project Reactor
Imagine an event processing service that consumes application events from a queue. It works well until one day, when it starts lagging. Events are processed with large delays, and the queues fill up. What happens? Most likely we experience a sudden spike of events and our service is not able to catch up. In this article we will learn how to solve the issue with reactive programming. We will create batches from individual events with Project Reactor library and buffer operator.
tl;dr;
When processing events from a queue, consider combining them into batches. Buffer operator from Reactor library may be very helpful.
Spike danger
Sudden spikes are dangerous, because they hit the weakest points of our system: hidden bottlenecks. When the volume of events is low, the bottlenecks are viewed as a minor issue and often get unnoticed. The spike creates a congestion that eventually propagates through all our services, disrupting them.
Right, we have autoscaling, but it is not a silver bullet. It is the most helpful, when we have stateless, independent service instances. In message processing systems, this is often not valid. For example, in Apache Kafka there is a maximum limit of distinct consumers that we can attach to a topic. It is equal to the number of topic partitions. Another type of spikes is not related to the volume, but unfortunate distribution of the events. Imagine a very simple situation:
- we have an event queue and 10 event consumers,
- we distribute each event to one of them, based on entity ID,
- someone triggers thousands of events for a single entity.
In this case, we will send all of them to a single consumer. At the same time, the remaining 9 will be idle.
Improving throughput
Very often, all we need to improve the throughput is looking at the design of our service. The event processors sometimes pass the events to another service or fetch extra data. A common bottleneck is sending the events further one-by-one. There are a couple of ways to solve it:
- combining 100 events into a batch and send them in a single request,
- merging related events,
- removing redundant/duplicate events.
As a result, we either send fewer events to downstream services, or we do it more efficiently. We will now see how to do it with reactive programming.
Sample code
Find a complete example on GitHub: zone84-examples/batches-reactor
Buffer operator
Creating batches is very easy with reactive programming. All we need is the family of buffer operators, present both in RxJava and Project Reactor. Basically, they collect a group of incoming items and emit a single collection with all of them. Below, you can find a diagram:
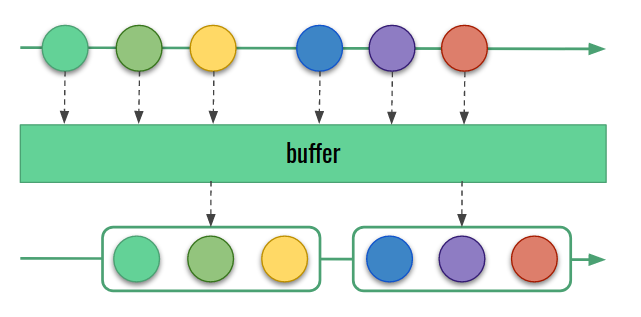
The main difference between individual operators is when we close the existing buffer and open the new one:
- size-based: wait until the buffer reaches some size,
- time-based: wait for the specified amount of time,
- custom constraint.
Size-based buffers are good for small streams with instantly available data. Otherwise, we may wait a long time until they fill up. On the other hand, time-based buffers can produce very large output collections on large traffic. Fortunately, there is also a combination of both: a buffer where we specify both the maximum size, and the maximum waiting time. This one is the best for our use case.
Batches and Project Reactor
Creating batches with Project Reactor library is very easy. Below, we can see an example code snippet. It filters out unwanted data, creates batches and allows us merging related events. We use only three operators for that:
Flux.fromIterable(new DataGenerator())
.subscribeOn(Schedulers.boundedElastic())
.filterWhen(event -> filter.eventAccepted(event)) // 1
.bufferTimeout(BUFFER_SIZE, BUFFER_TIMESPAN) // 2
.flatMapSequential(batch -> Flux.fromIterable(merger.merge(batch))) // 3
.subscribe(event -> LOG.info("Event received: " + event),Explanation:
- Before we write an event into the buffer, we may want to filter out some unwanted events. The operator
filterWhen()is very useful here – it allows checking the condition asynchronously. The shownfilter.eventAccepted()call should returnMono<Boolean>. In RxJava, there is no such operator, but we can useflatMapSingle()orflatMapMaybe()instead. - Here we produce the actual batches. The operator has both the size and time limit.
- Here we can consume the buffer, and merge a group of related events into a single event. However, beware of the operators. If the order of events is important for us, we need to use
flatMapSequential()to preserve the order during processing. With regularflatMap(), the buffers may get reordered.
The buffer parameters should be reasonably low, and fine-tuned for our use case. Definitely the timespan should be short, so that we don’t add additional latency. I suggest starting with 100 ms and the size of 100, and then modify them.
Is it better now?
Let’s take a look at the results. We want to check how many events per second the last subscriber receives. I updated the example application to measure that, and then – to collect identical results for the version without batching. In both cases, the application produced exactly the same events.
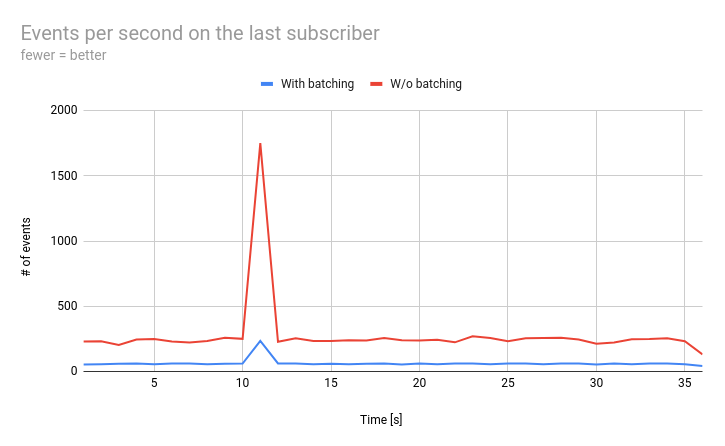
As we can see, for most of the time we had an average flow, but there was also one spike. The batching helped us in both cases. For average flow, it reduced the number of events from approx. 236 to 56. The results for spike are even more impressive. It was flattened from 1752 to just 234 events per second (7.5x better).
Note that in the example application, different types of events are uniformly distributed. Therefore there is a good chance that in a single buffer, we will have a lot of events to merge. In real world, the distribution may be different, and the ratios depend on it.
Corner case
We must remember that batching is a heuristic process. A fraction of second decides whether two events will be merged or not. For this reason, the receiver can never assume that the merging will actually happen. Imagine that we process change events about links between users and subscribed services. To make it more tricky, let’s say that we update user links by deleting them all, and inserting again. Don’t laugh – this is how Hibernate ORM actually manages element collections in entities. If we translate the changes into events, we get a sequence of DELETES followed by INSERTS. Now we can think: “OK, receiving a delete event disables the subscription, so let’s merge the corresponding pairs of DELETE and INSERT into an UPDATE event”.
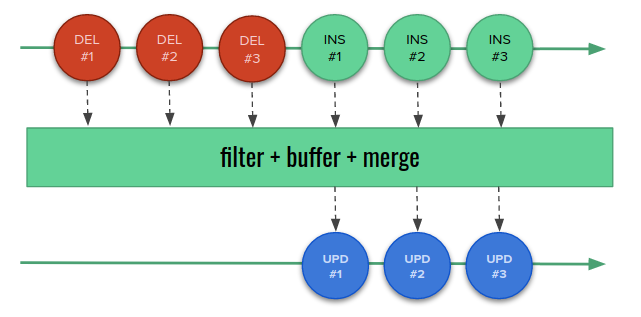
The tests show that it works, and we avoid disabling the subscriptions. We release it to the production with confidence. Unfortunately, after some time we start getting complaints about brief terminations of the subscriptions. What happens? It turns out that we don’t merge all DELETE/INSERT pairs in certain situations:
- the list of user subscriptions is larger than the buffer size: in this case, DELETES fill the entire buffer (or more), and INSERTS also land in separate buffers. The merger has no chance of noticing them,
- the queue receives also many other events and our DELETE-INSERT pairs are almost always separated by them, so that they land in distinct buffers.
Our mistake is that we use an unreliable process to solve a deterministic business logic challenge. Remember that such an automatic batching is only about performance. Do not make it a part of your core logic.
In short…
Do not use non-deterministic batching to solve business logic challenges that require a consistent behavior.
Conclusion
As we can see, Project Reactor allows creating batches in almost declarative way. However, let’s remember that it does not remove the complexity. We must still understand, where to apply it and how it will affect our system.
Sample code
Find a complete example on Github: zone84-examples/batches-reactor
